목차
라이브러리 다운로드
pip install pytesseract pillowTesseract-OCR 엔진
Tesseract-OCR 엔진을 별도로 설치해야함
윈도우 환경에서는 아래 링크에서 다운로드
https://github.com/UB-Mannheim/tesseract/wiki
macOS: Homebrew를 사용하여 설치
brew install tesseract환경 변수 삽입
윈도우 환경이라면 환경 변수 설정 필요 (코드에 경로 적어도 무방)
윈도우 검색 창에 “환경”를 입력하고 “시스템 환경 변수 편집”을 클릭
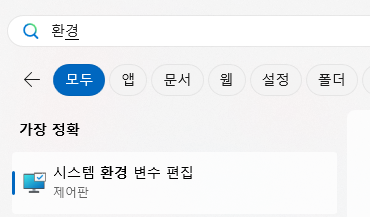
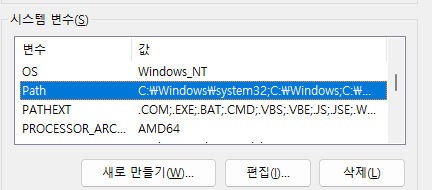
환경 변수(하단 위치) > 시스템 변수 > Path 에 Tesseract-OCR 설치한 경로 입력
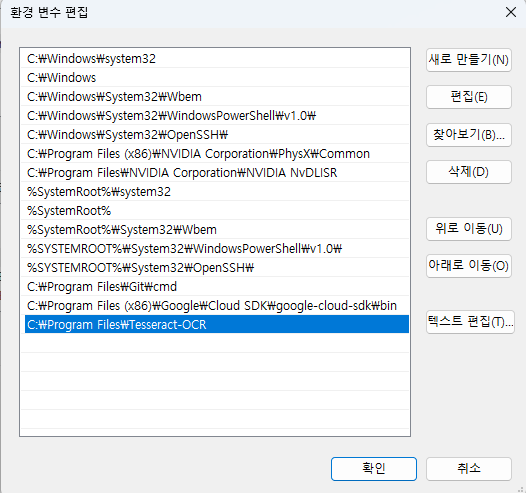
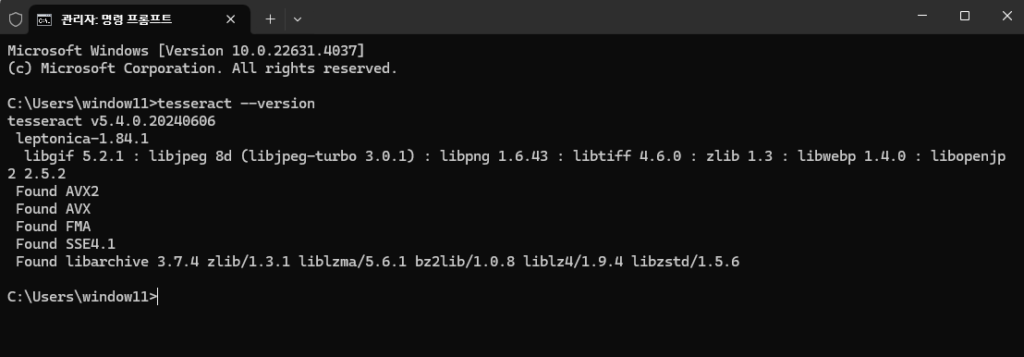
설치 확인
CMD > 터미널에서
tesseract --version정상 설치 확인한다.
한국어 언어 추가
기본 설치에는 영어만 있음
한국어는 별도로 다운로드 필요 아래 링크에서 확인
https://github.com/tesseract-ocr/tessdata

kor.traineddata 다운로드 받아 C:\Program Files\Tesseract-OCR\tessdata 복사
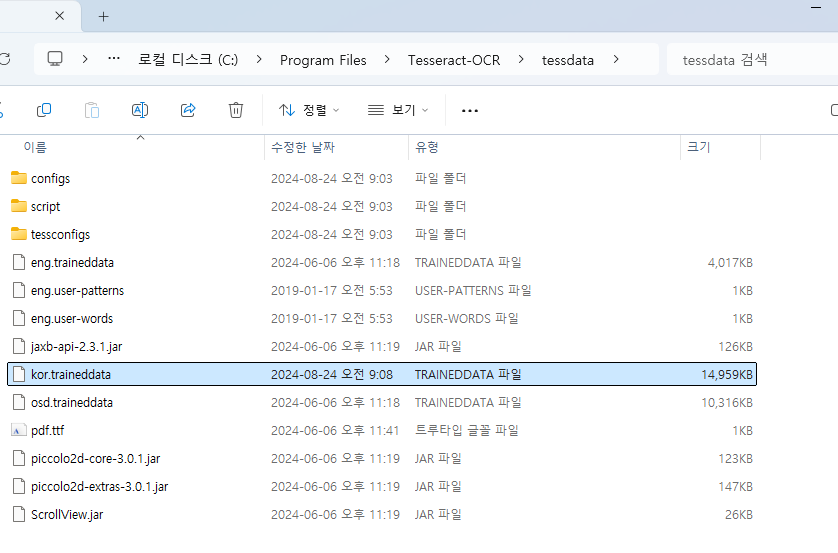
여기까지 했다면 환경 설정 완료
설전 테스트
import pyautogui
import io
from PIL import Image
import pytesseract
from PIL import Image
# 특정 영역 캡처 (예: (x=0, y=0)에서 시작하여 너비=300, 높이=400인 영역)
region = (0, 190, 220, 40)
screenshot = pyautogui.screenshot(region=region)
# 스크린샷 이미지를 메모리 내에서 저장하기 위해 BytesIO 사용
buffered = io.BytesIO()
screenshot.save(buffered, format="PNG")
screenshot.show()
# 이미지 파일을 저장할 경로와 파일명
file_path = "image\\screenshot_temp.png"
# 스크린샷을 파일로 저장
screenshot.save(file_path)
print(f"스크린샷이 저장되었습니다: {file_path}")
# 스크린샷 저장 경로 리스트화
image_list = [file_path]
# Tesseract 경로 설정 (필요한 경우)
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 이미지 파일 열기
image = Image.open(file_path)
# 이미지에서 텍스트 추출
text = pytesseract.image_to_string(image)
print(text)위 코드는 해당 좌표의 스크린 샷 찍고 이미지를 텍스트로 변환한다.
영어

위 스크린샷을 텍스트 한 결과
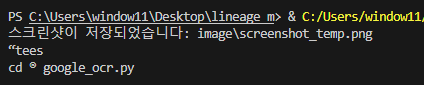
얼추 정확하다
한글
한글의 경우 코드에서 수정이 필요
text = pytesseract.image_to_string(image, lang='kor')언어 선택안하면 무조건 영어번역이다.

위 이미지 텍스트화 결과
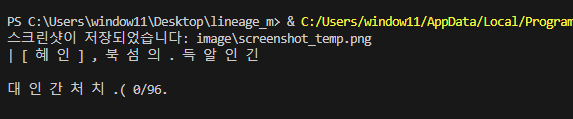
한글은 노답
그렇다면 좀 더 정돈된 이미지는 어떨까?
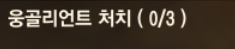
위 이미지로 실행한 결과
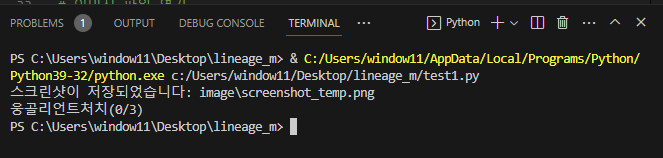
오 아주 제법이다.